library(tidyverse)
library(here)
source(here("R", "theme_course.R"))
theme_set(theme_course())3 Gramatyka grafiki
ggplot2 opiera się na prostej idei: wykres składamy z danych, mapowań, geometrii, skal, statystyk, podziału na panele (faceting) i motywu. Dzięki temu zamiast pamiętać setki funkcji, uczymy się jednego spójnego języka.
3.1 Dane i mapowania estetyczne (aesthetics)
mpg_local <- readr::read_csv(
here("datasets", "mpg.csv"),
show_col_types = FALSE
) |>
mutate(
cylinders = factor(cylinders),
origin = factor(
recode(origin, usa = "USA", europe = "Europa", japan = "Japonia"),
levels = c("USA", "Europa", "Japonia")
)
)
insurance <- readr::read_csv(
here("datasets", "insurance_premiums.csv"),
show_col_types = FALSE
) |>
janitor::clean_names() |>
mutate(
region = factor(
recode(
region,
Midwest = "Środkowy Zachód",
Northeast = "Północny Wschód",
South = "Południe",
West = "Zachód"
),
levels = c("Środkowy Zachód", "Północny Wschód", "Południe", "Zachód")
)
)
mpg_local |>
select(mpg, cylinders, displacement, horsepower, weight, origin) |>
slice_head(n = 6)mpg_local |>
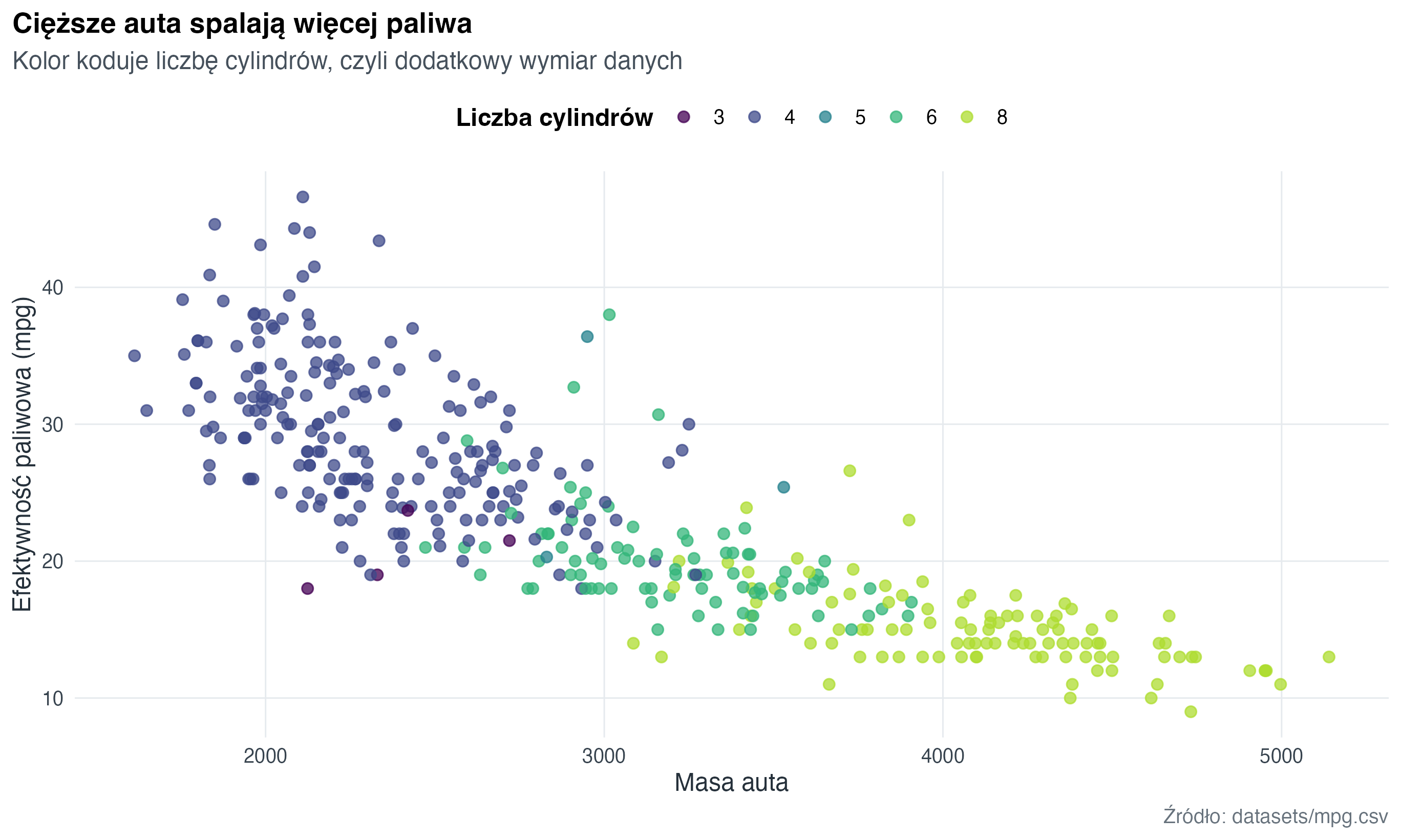
ggplot(aes(x = weight, y = mpg, colour = cylinders)) +
geom_point(alpha = 0.75, size = 2.2) +
scale_colour_course_d(name = "Liczba cylindrów") +
labs(
title = "Cięższe auta spalają więcej paliwa",
subtitle = "Kolor koduje liczbę cylindrów, czyli dodatkowy wymiar danych",
x = "Masa auta",
y = "Efektywność paliwowa (mpg)",
caption = "Źródło: datasets/mpg.csv"
)
3.2 Warstwa statystyczna (statistical layer)
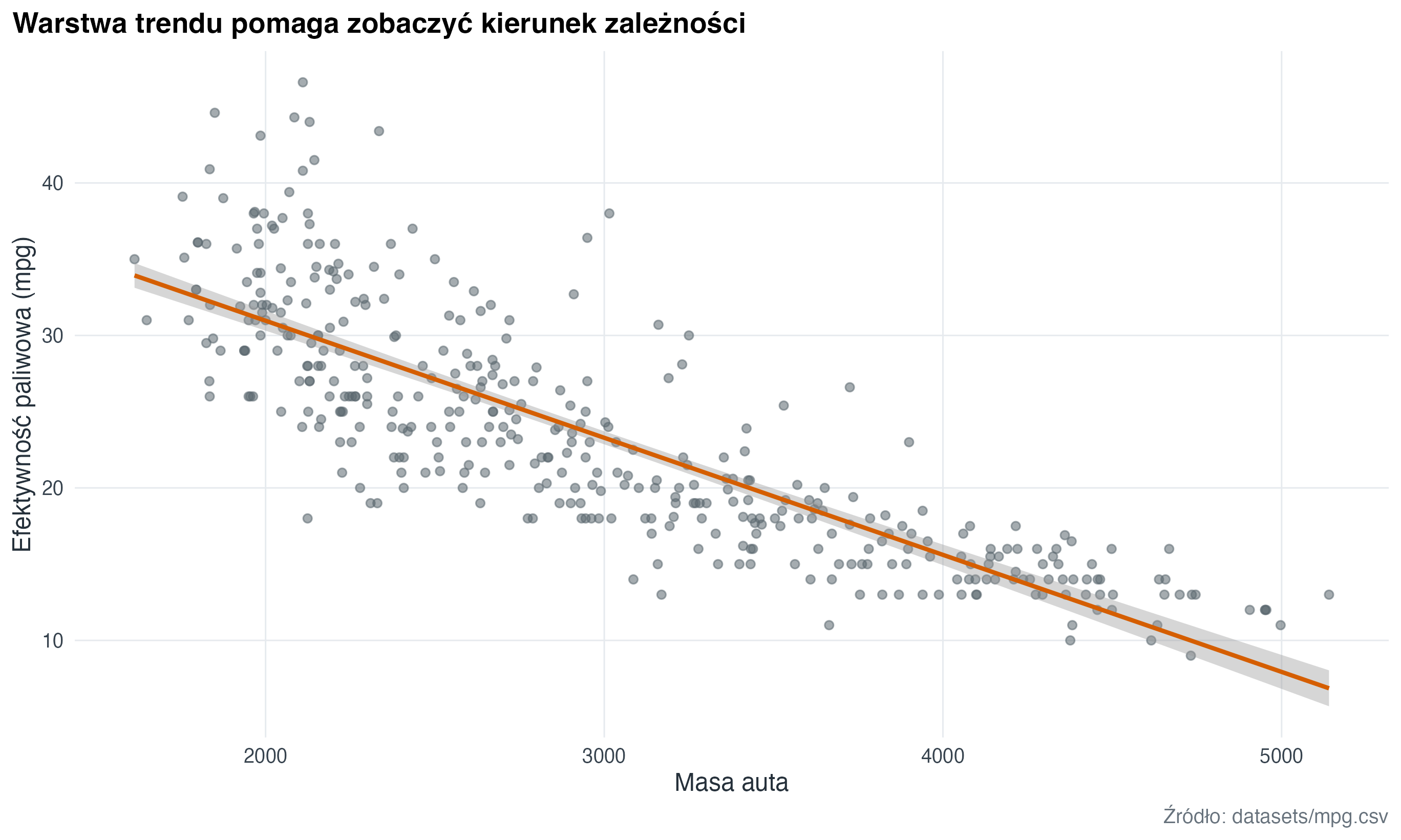
Ta sama baza danych może dostać dodatkową warstwę modelu. Na tym etapie najważniejsze jest to, że warstwy można dodawać bez przebudowy całego wykresu.
mpg_local |>
ggplot(aes(x = weight, y = mpg)) +
geom_point(alpha = 0.55, colour = "#5B6770") +
geom_smooth(method = "lm", se = TRUE, colour = "#D55E00", linewidth = 1) +
labs(
title = "Warstwa trendu pomaga zobaczyć kierunek zależności",
x = "Masa auta",
y = "Efektywność paliwowa (mpg)",
caption = "Źródło: datasets/mpg.csv"
)
3.3 Regresja i podział na panele
W tej części budujemy dwa warianty tej samej analizy: jeden wykres z linią regresji dla całego zbioru oraz wersję podzieloną na panele. Dzięki temu widać, że w ggplot2 zmieniamy strukturę wykresu przez dodawanie warstw, a nie przez przeskakiwanie między osobnymi funkcjami.
insurance |>
ggplot(aes(x = insurance_losses, y = premiums)) +
geom_point(aes(colour = region), alpha = 0.78, size = 2.4) +
geom_smooth(
data = insurance,
aes(x = insurance_losses, y = premiums),
method = "lm",
se = TRUE,
colour = "#D55E00",
fill = "#F0E442",
linewidth = 1,
inherit.aes = FALSE
) +
scale_colour_course_d(name = "Region USA") +
scale_y_continuous(labels = scales::label_dollar()) +
labs(
title = "Regresja jako dodatkowa warstwa, nie osobna funkcja",
subtitle = "Kolor pokazuje region, a linia streszcza relację dla całych danych",
x = "Straty ubezpieczeniowe",
y = "Składka",
caption = "Źródło: datasets/insurance_premiums.csv"
)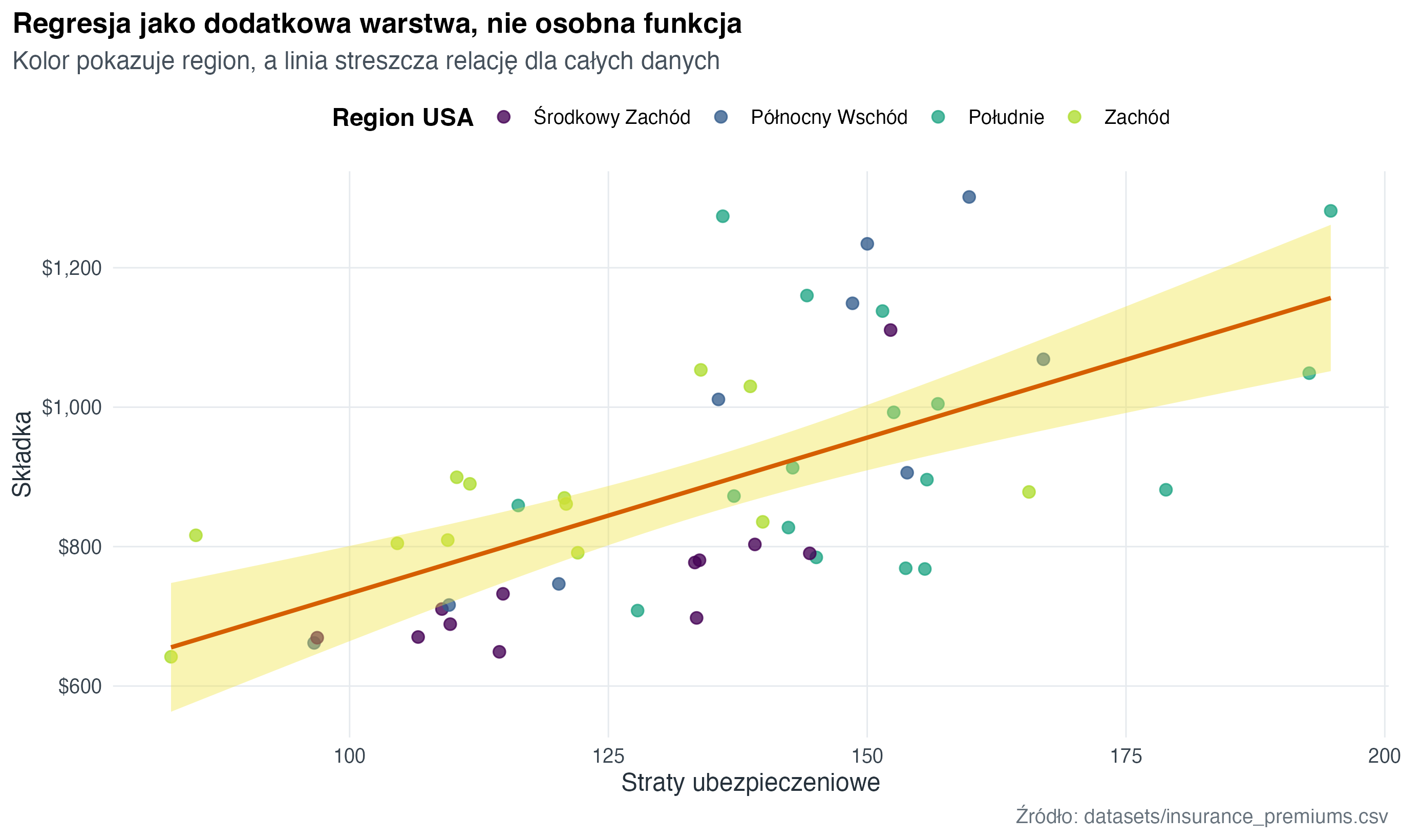
ggplot2: punkty i jeden trend liniowy.
insurance |>
ggplot(aes(x = insurance_losses, y = premiums)) +
geom_point(alpha = 0.65, colour = "#5B6770", size = 2.1) +
geom_smooth(method = "lm", se = FALSE, colour = "#D55E00", linewidth = 0.9) +
facet_wrap(vars(region)) +
scale_y_continuous(labels = scales::label_dollar()) +
labs(
title = "Podział na panele rozdziela model na regiony",
x = "Straty ubezpieczeniowe",
y = "Składka"
)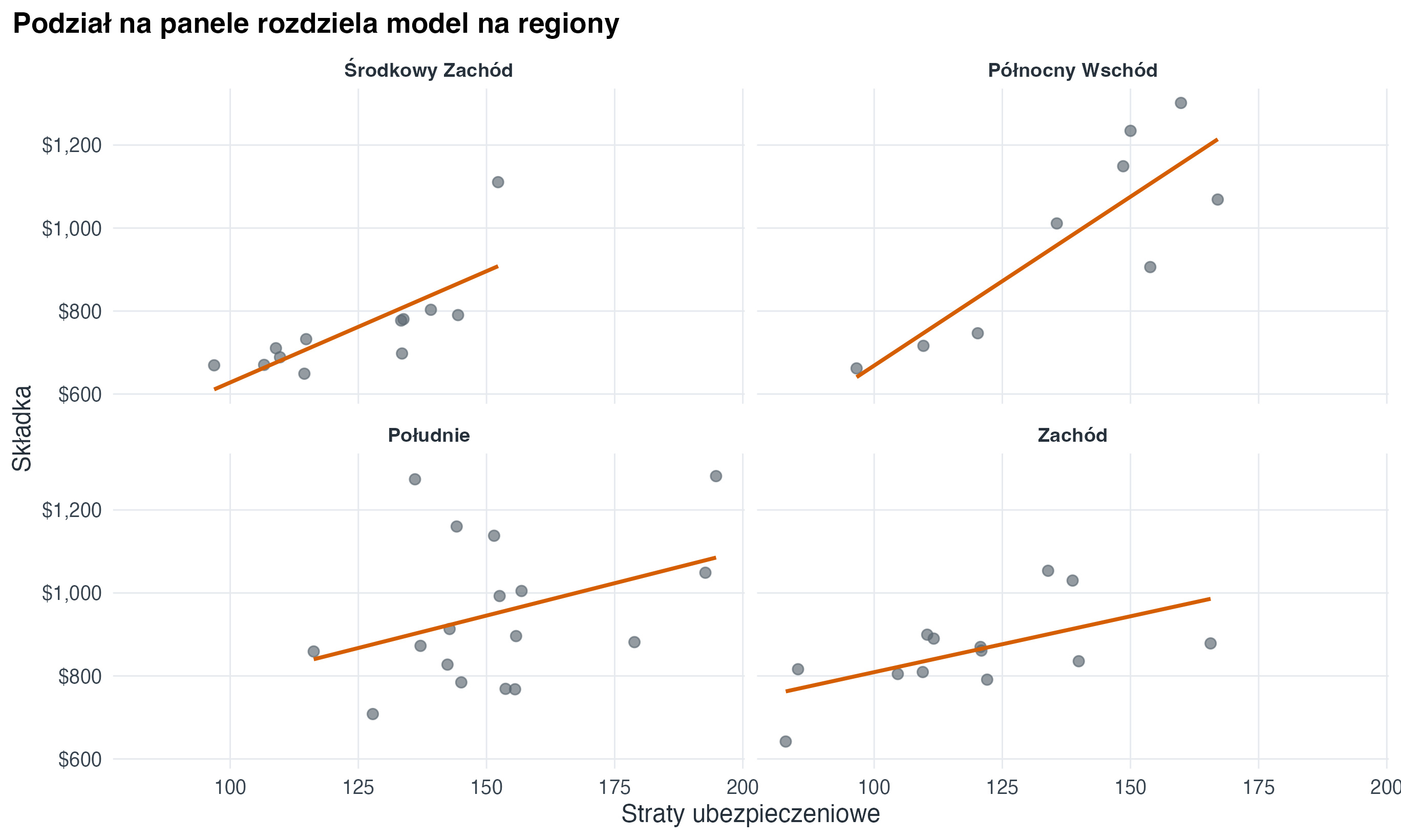
ggplot2.
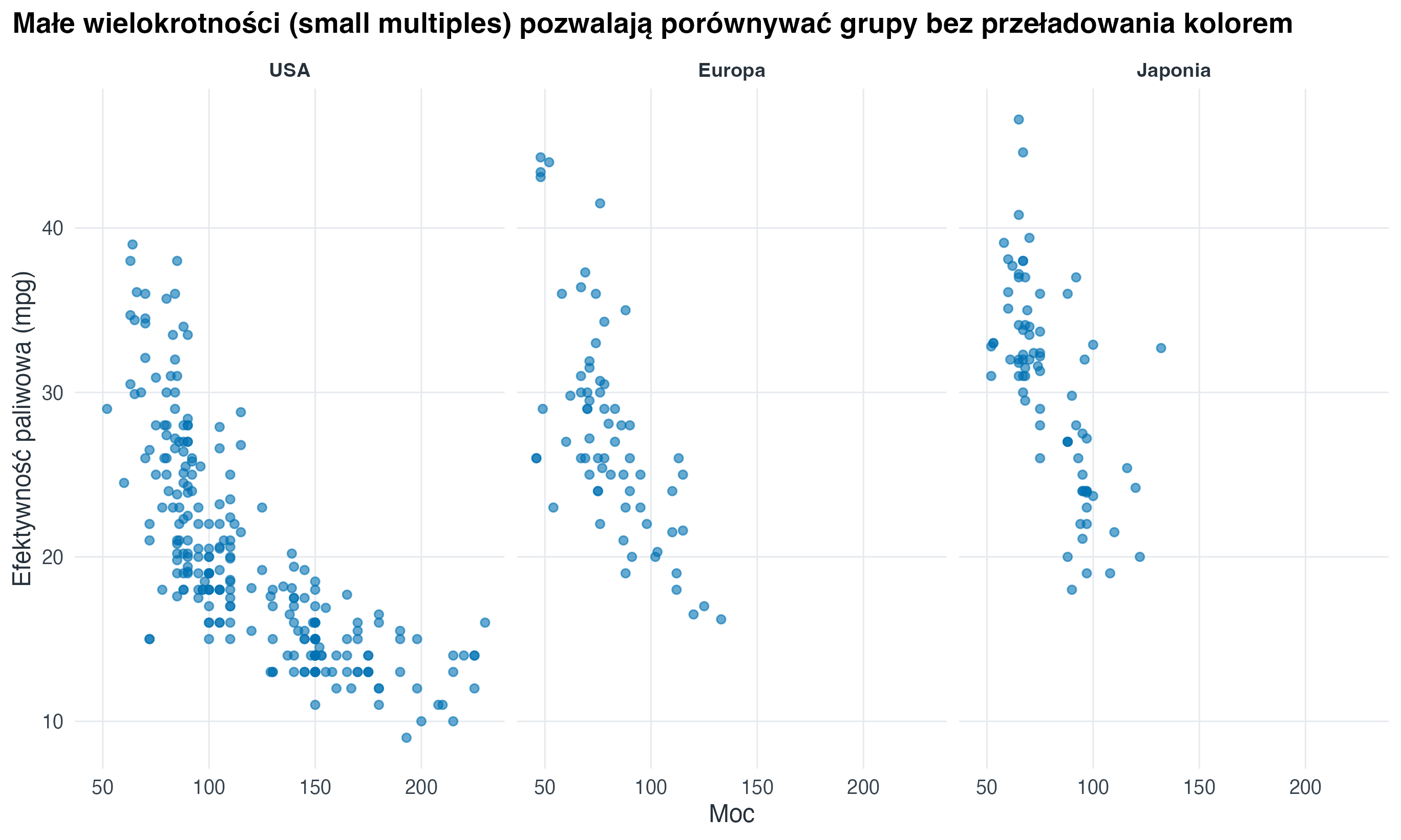
3.4 Podział na panele (faceting)
mpg_local |>
ggplot(aes(x = horsepower, y = mpg)) +
geom_point(alpha = 0.6, colour = "#0072B2") +
facet_wrap(vars(origin)) +
labs(
title = "Małe wielokrotności (small multiples) pozwalają porównywać grupy bez przeładowania kolorem",
x = "Moc",
y = "Efektywność paliwowa (mpg)"
)
3.5 Zadanie
Zbuduj wykres horsepower kontra acceleration. Najpierw użyj koloru dla cylinders, potem podziel wykres na panele przez facet_wrap(vars(cylinders)). Która wersja jest łatwiejsza do przeczytania?